Data Scraping Vs Information Crawling What Is The Difference? This difference has vital ramifications for the devices and techniques utilized in each process. Worldwide of data collection and evaluation, 2 terms that you may have discovered are web scuffing and web crawling. Both strategies are used to remove information from internet sites, however they stand out processes with unique features. Something you should understand with internet crawlers is that some web sites may not want robots searching through their web pages. Some sites will certainly block certain web spiders making use of a robots.txt data. This can avoid particular crawling representatives from indexing a website's web pages, however they do not avoid web content from being indexed by online search engine. Any kind of pertinent data is then gathered and exported to a various style. Some individuals will certainly place the scuffed details into a spread sheet, a database, or do further handling with an API. This method can likewise be made use of to identify and locate target information from web pages. But in the case of internet scratching, we understand precisely which internet API integration case studies information we require to essence. For instance, it could be an HTML aspect framework for a specific web page. Nonetheless, some blocks might Top API integration companies be overwhelming both to an internet scrape and a web spider. Information scuffing is a legal data removal due to the fact that every web page that you'll obtain info from is publicly readily available. To make best use of the efficiency of the scraping process, brand names can rely upon artificial intelligence and artificial intelligence strategies.
Wix will let you build an entire website using only AI prompts - The Verge
Wix will let you build an entire website using only AI prompts.
Posted: Tue, 18 Jul 2023 07:00:00 GMT [source]
Discover More About Internet Scuffing
They go deeper right into an internet site than a hands-on scan would allow because they discover web links and web pages that could not be noted in conveniently available locations of a site. You'll additionally hear internet crawlers referred to as internet spiders or crawler crawlers. You could not recognize every one of the web pages that a website has readily available up until you use a bot. They allow you understand what content is offered and where it is located, yet they don't really gather information for you. You can likewise develop your very own custom automated web scrapers if you have some programming knowledge. This will certainly offer you extra control over what data you remove from internet sites, however it can take a significant quantity of time.First identification of an evolving Middle Stone Age ochre culture at ... - Nature.com
First identification of an evolving Middle Stone Age ochre culture at ....
Posted: Fri, 08 Sep 2023 07:00:00 GMT [source]
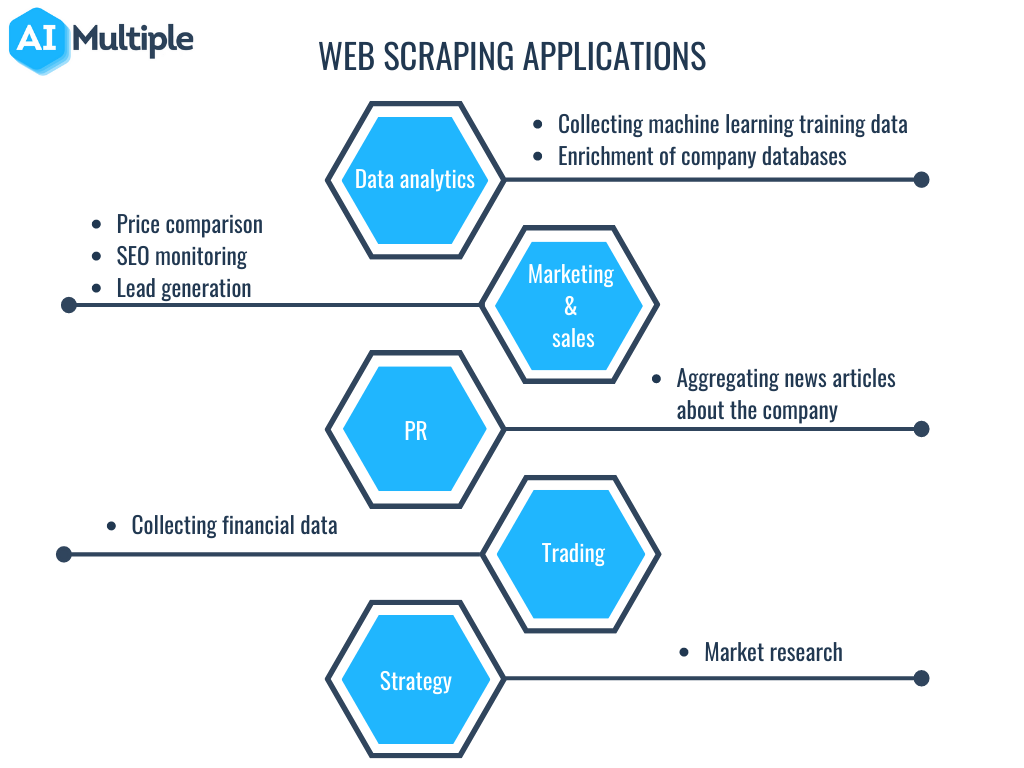
Significant Victory For Social Media Scuffing
Bots and spiders will certainly browse all back links and will not stop till it examines every little thing that is from another location linked. Information crawling is done on a large scale that needs additional precautions so as not to annoy the source or break any legislations. This procedure is needed to filter and separate different types of raw information from different sources right into something insightful and functional. It can pull points out such as asset rates and harder to reach information. This is because the technique does not omit duplicates from the various resources where it draws out the data.- The short variation is that internet scratching has to do with removing the information from several web sites.If you are looking for more info about the proxy and exactly how you can use it for your service, you can find even more info below.In contrast to the straightforward Google Sheets, PDF files are safely secured away from editing and copying data.Information scuffing is done on little and large ranges, while data creeping is typically done on a large scale.Learning the differences between both methods will aid you decide which method suits your project, what information you need, and what to do with the information after accumulating.